基准测试
说明: 借用 MogoDB 工程师 Patrick 的文章来了解 Rust 里做基准测试基本姿势。
原文: https://patrickfreed.github.io/rust/2021/10/15/making-slow-rust-code-fast.html
使用 Criterion.rs 和 火焰图(flamegraphs) 进行性能调优
性能是开发者为其应用程序选择 Rust 的首要原因之一。事实上,它是 rust-lang.org 主页上 "为什么选择Rust?"一节中列出的第一个原因,甚至在内存安全之前。这也是有原因的,许多基准测试表明,用Rust编写的软件速度很快,有时甚至是最快的。但这并不意味着所有用Rust编写的软件都能保证快速。事实上,写低性能的Rust代码是很容易的,特别是当试图通过Clone 或Arc替代借用来""安抚""借用检查器时,这种策略通常被推荐给 Rust 新手。这就是为什么对 Rust 代码进行剖析和基准测试是很重要的,可以看到任何瓶颈在哪里,并修复它们,就像在其他语言中那样。在这篇文章中,我将根据最近的工作经验,展示一些基本的工具和技术,以提高 mongodb crate 的性能。
注意:本帖中使用的所有示例代码都可以在这里找到。
索引
性能剖析
在进行任何性能调优工作时,在试图修复任何东西之前,绝对有必要对代码进行性能剖析(profiling),因为瓶颈往往位于意想不到的地方,而且怀疑的瓶颈往往不如你想的那样对性能有足够影响。如果不遵守这一原则,就会导致过早优化,这可能会不必要地使代码复杂化并浪费开发时间。这也是为什么建议新人在开始的时候自由地 Clone ,这样可以帮助提高可读性,而且可能不会对性能产生严重的影响,但是如果他们这样做了,以后的性能剖析会发现这一点,所以在那之前没有必要担心。
过早优化(Premature Optimization)
Premature optimization is the root of all evil. -- DonaldKnuth
在 DonaldKnuth 的论文 《 Structured Programming With GoTo Statements 》中,他写道:"程序员浪费了大量的时间去考虑或担心程序中非关键部分的速度,而当考虑到调试和维护时,这些对效率的尝试实际上会产生强烈的负面影响。我们应该忘记这种微小的效率,比如说因为过早优化而浪费的大约97%的时间。然而,我们不应该放弃那关键的 3% 的机会"。
基准测试
剖析的第一步是建立一套一致的基准,可以用来确定性能的基线水平,并衡量任何渐进的改进。在 mongodb 的案例中,标准化的MongoDB 驱动微基准集在这方面发挥了很好的作用,特别是因为它允许在用其他编程语言编写的MongoDB驱动之间进行比较。由于这些是 "微 "基准,它们还可以很容易地测量单个组件的变化(例如,读与写),这在专注于在特定领域进行改进时是非常有用的。
一旦选择了基准,就应该建立一个稳定的环境,可以用来进行所有的定时测量。确保环境不发生变化,并且在分析时不做其他 "工作"(如浏览猫的图片),这对减少基准测量中的噪音很重要。
用 cargo bench 和 Criterion.rs 来执行基准测试
Rust 提供的基准测试只能在 Nightly 下使用,因为它还未稳定。它对简单的基准测试比较有用,但是功能有限,而且没有很好的文档。另一个选择是 criterion crate。它为基准测试提供了更多的可配置性和丰富的功能支持,同时支持稳定的Rust !我将详细介绍基本的 criterion crate。
我将在这里详细介绍一个基本的 criterion 设置,但如果想了解更多信息,我强烈推荐你查看优秀的 Criterion.rs 用户指南。
在对mongodb进行基准测试时,我首先使用cargo new <my-benchmark-project>创建了一个新项目,并在Cargo.toml中添加了以下几行。
[dependencies]
tokio = { version = "1", features = ["full"] }
futures = { version = "0.3", default-features = false }
mongodb = { path = "/home/patrick/mongo-rust-driver" }
[dev-dependencies]
criterion = { version = "0.3.5", features = ["async_tokio", "html_reports"] }
[[bench]]
name = "find"
harness = false
在我的基准测试中,使用了 tokio 异步运行时,所以我需要把它指定为一个依赖项,并启用async_tokio的 criterion features,但如果你不使用tokio,这不是必需的。我还需要使用futures crate提供的一些功能,但这对于运行一个criterion 基准来说也是没有必要的。对于我的mongodb依赖,我指定了一个本地克隆库的路径,这样我就可以对我做的任何改动进行基准测试。另外,在这个例子中,我将专注于对mongodb crate的Collection::find方法进行基准测试,所以我对基准进行了相应的命名,但你可以对你的基准测试进行任意命名。
接下来,需要创建一个benches/find.rs文件来包含基准测试。文件名需要与Cargo.toml中的名称字段中指定的值相匹配。下面是一个测试Collection::find性能的简单基准测试的例子。
#![allow(unused)] fn main() { use criterion::{criterion_group, criterion_main, Criterion}; use futures::TryStreamExt; use mongodb::{ bson::{doc, Document}, Client, }; pub fn find_bench(c: &mut Criterion) { // begin setup // create the tokio runtime to be used for the benchmarks let rt = tokio::runtime::Builder::new_multi_thread() .enable_all() .build() .unwrap(); // seed the data server side, get a handle to the collection let collection = rt.block_on(async { let client = Client::with_uri_str("mongodb://localhost:27017") .await .unwrap(); let collection = client.database("foo").collection("bar"); collection.drop(None).await.unwrap(); let doc = doc! { "hello": "world", "anotherKey": "anotherValue", "number": 1234 }; let docs = vec![&doc; 10_000]; collection.insert_many(docs, None).await.unwrap(); collection }); // end setup c.bench_function("find", |b| { b.to_async(&rt).iter(|| { // begin measured portion of benchmark async { collection .find(doc! {}, None) .await .unwrap() .try_collect::<Vec<Document>>() .await .unwrap(); } }) }); } criterion_group!(benches, find_bench); criterion_main!(benches); }
find_bench函数包含设置和运行基准的所有代码。该函数可以被任意命名,但是它需要接收一个&mut Criterion作为参数。该函数的第一部分包含设置代码,在基准运行前只执行一次,其运行时间根本不被测量。实际测量的部分是稍后被传入Bencher::iter的闭包。该闭包将被多次运行,每次运行的时间将被记录、分析,并包含在一个HTML报告中。
在这个特定的例子中,设置涉及到创建tokio运行时,该运行时将用于基准测试的其余部分。通常,这是在幕后通过tokio::main宏完成的,或者,在库的情况下,根本就不需要。然而,我们需要在这里手动创建一个运行时,以便我们以后可以通过Bencher::to_async方法将其传递给criterion。一旦运行时被创建,设置就会继续进行,即填充我们在实际基准中要查询的MongoDB集合。由于这涉及到异步API的使用,我们需要通过Runtime::block_on确保它们在异步运行时的上下文中执行。在实际测量部分,我们对设置时创建的集合中的所有文档进行查询。
所有这些都准备好了(并且我们的MongoDB实例正在运行),我们可以运行cargo bench来建立我们的基线。输出结果将如下。
#![allow(unused)] fn main() { ~/benchmark-example$ cargo bench Finished bench [optimized] target(s) in 0.07s Running unittests (target/release/deps/benchmark_example-b9c25fd0639c5e9c) running 0 tests test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s Running unittests (target/release/deps/find-e1f66bfc9cf31158) Gnuplot not found, using plotters backend Benchmarking find: Warming up for 3.0000 s find time: [55.442 ms 55.663 ms 55.884 ms] }
这里最重要的信息是时间: [55.442 ms 55.663 ms 55.884 ms]。中间的值是对每次迭代所花时间的最佳估计,第一个和最后一个值定义了置信区间(Confidence interval)的上界和下界。默认情况下,使用的置信度是95%,这意味着该区间有95%的机会包含迭代的实际平均运行时间。关于这些值以及如何计算的更多信息,请查看Criterion.rs用户指南。
现在,如果我们再次执行cargo bench,它将记录更多的时间,并与之前的时间进行比较(之前的数据存储在目标/标准中),报告任何变化。鉴于我们根本没有改变代码,这应该报告说没有任何变化。
#![allow(unused)] fn main() { find time: [55.905 ms 56.127 ms 56.397 ms] change: [+0.3049% +0.8337% +1.4904%] (p = 0.01 < 0.05) Change within noise threshold. Found 5 outliers among 100 measurements (5.00%) 1 (1.00%) low mild 2 (2.00%) high mild 2 (2.00%) high severe }
正如预期的那样,criterion 报告说,与上次运行相比,任何性能的变化都可能是由于噪音造成的。现在我们已经建立了一个基线,现在是时候对代码进行剖析,看看它哪里慢。
火焰图生成
perf 是一个Linux命令行工具,可以用来获取一个应用程序的性能信息。我们不会直接使用它,而是通过flamegraph crate,它是一个基于Rust的flamegraph生成器,可以与cargo一起工作。
火焰图(Flamegraphs)是程序在每个函数中花费时间的有用的可视化数据。在被测量的执行过程中调用的每个函数被表示为一个矩形,每个调用栈被表示为一个矩形栈。一个给定的矩形的宽度与在该函数中花费的时间成正比,更宽的矩形意味着更多的时间。火焰图对于识别程序中的慢速部分非常有用,因为它们可以让你快速识别代码库中哪些部分花费的时间不成比例。
要使用cargo生成flamegraphs,首先我们需要安装perf和flamegraph crate。这在Ubuntu上可以通过以下方式完成。
#![allow(unused)] fn main() { sudo apt-get install linux-tools-common linux-tools-`uname -r` cargo install flamegraph }
一旦安装完成,我们就可以生成我们的基线的第一个flamegraph! 要做到这一点,请运行以下程序。
#![allow(unused)] fn main() { cargo flamegraph --bench find -o find-baseline.svg -- --bench }
然后你可以在浏览器中打开find-baseline.svg来查看火焰图。如果你在运行cargo flamegraph时遇到权限问题,请参阅flamegraph crate的README中的说明。
生成 criterion 基准的flamegraph可能会有噪音,因为很多时间都花在了 criterion(例如测量时间)和设置上,而不是在被基准测试的部分。为了减少火焰图中的一些噪音,你可以写一个与基准的测量部分行为类似的程序,然后生成另一个火焰图来代替。
例如,我用下面的命令从一个普通的二进制程序中生成一个火焰图,该程序使用我的本地mongodb crate副本来执行没有criterion的查找。
cargo flamegraph --bin my-binary -o find-baseline.svg
这里是生成的火焰图(在新的浏览器标签页中打开它来探索)。

现在我们可以看到时间花在哪里了,现在是时候深入研究,看看我们是否能找到瓶颈。
识别火焰图中的瓶颈
火焰图中的栈从底部开始,随着调用栈的加深而向上移动(左右无所谓),通常这是开始阅读它们的最佳方式。看一下上面火焰图的底部,最宽的矩形是Future::poll,但这并不是因为Rust 的 Future 超级慢,而是因为每个.await都涉及轮询(poll)Future。考虑到这一点,我们可以跳过任何轮询矩形,直到我们可以在mongodb中看到我们关心的信息的函数。下面火焰图的注释版本,突出了需要注意的部分。
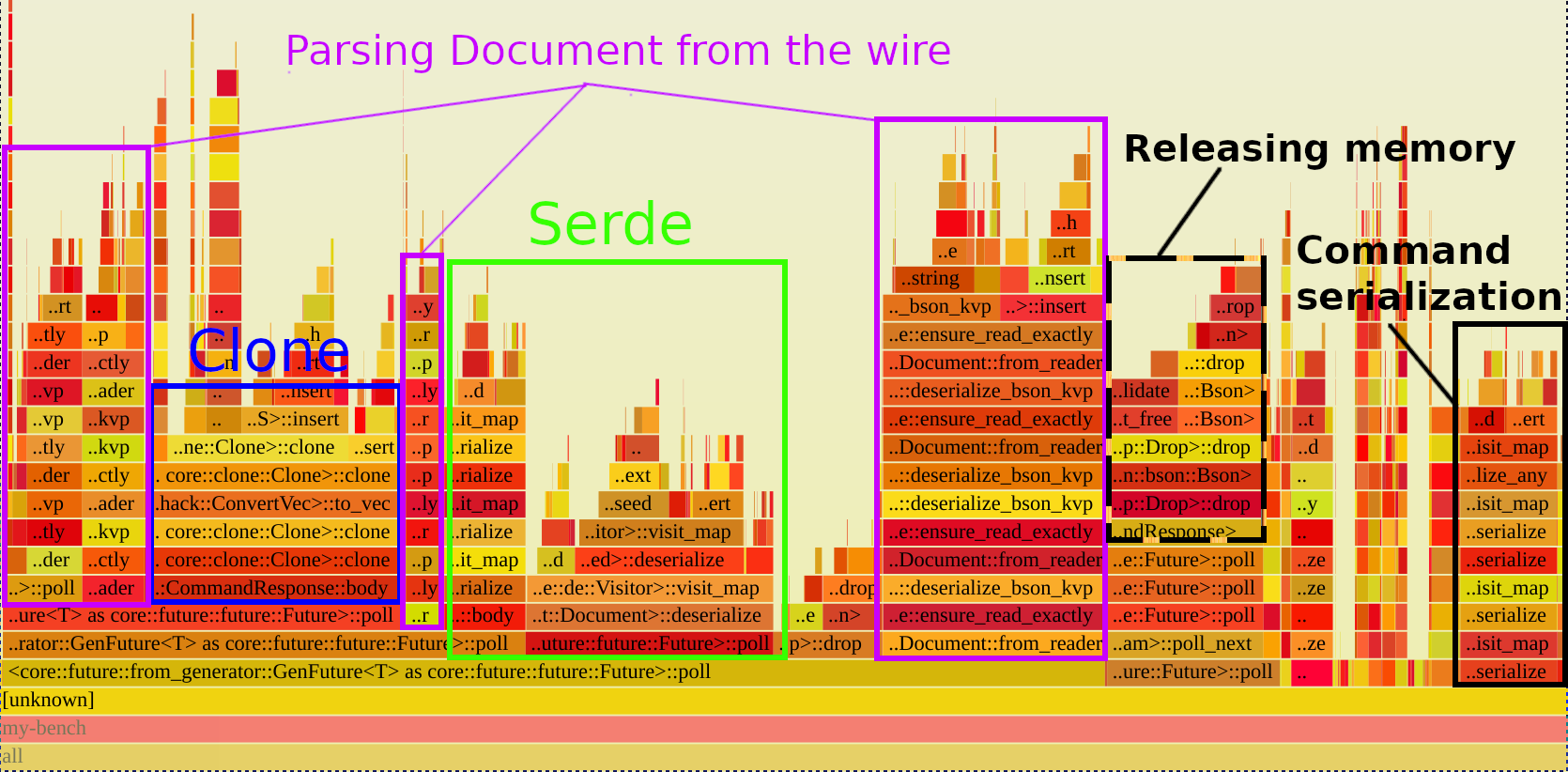
蓝色方块包含了调用CommandResponse::body所花费的时间,它显示几乎所有的时间都花在了clone()上。各个紫色矩形对应的是将BSON(MongoDB使用的二进制格式)解析到Document中所花费的时间,绿色矩形对应的是Document的serde::Deserialize实现中所花费的时间。最后,黑色虚线矩形对应的是释放内存的时间,黑色实线对应的是将命令序列化为BSON的时间。
现在我们知道了大部分时间花在哪里(只在少数几个地方),我们可以集中精力实际改变代码,使其更快。
Clone的“袭击”
无论做任何事,从最容易实现的地方开始,往往可以产生最好的回报。在这个例子中,只是 clone 就花费了一大块时间,所以我们能简单地消除 clone。从火焰图里知道,最昂贵的clone 就是 CommandResponse::body 中调用的那个,所以我们去看看这个方法。
在 command.rs:149 行,我们看到如下定义:
#![allow(unused)] fn main() { /// Deserialize the body of the response. pub(crate) fn body<T: DeserializeOwned>(&self) -> Result<T> { match bson::from_bson(Bson::Document(self.raw_response.clone())) { Ok(body) => Ok(body), Err(e) => Err(ErrorKind::ResponseError { message: format!("{}", e), } .into()), } } }
我们可以看到,这里确实有一个对clone的调用,所以它很可能是我们在火焰图中看到的耗费大量时间的那个。clone是必须的,因为我们需要从self所拥有的raw_response中反序列化,但我们只有对self的引用,所以我们不能从其中移出(move out)。我们也不能通过引用来使用raw_response,因为bson::from_bson期望一个有所有权的值。让我们研究一下 body 本身被调用的地方,看看我们是否可以改变它以获得 self 的所有权,从而避免clone。
具体来看这个基准的使用情况,在Find::handle_response中,查找操作使用它来反序列化服务端上的response。
#![allow(unused)] fn main() { fn handle_response(&self, response: CommandResponse) -> Result<Self::O> { let body: CursorBody = response.body()?; Ok(CursorSpecification::new( self.ns.clone(), response.source_address().clone(), body.cursor.id, self.options.as_ref().and_then(|opts| opts.batch_size), self.options.as_ref().and_then(|opts| opts.max_await_time), body.cursor.first_batch, ))} }
正如我们在这里看到的,response只在调用body后使用了一次,而且这一次的使用可以在它之前没有问题,所以如果 body 取得了self的所有权,这个调用点至少还能工作。对其余的调用点重复这个过程,我们看到body实际上可以取得self的所有权,从而避免clone,所以让我们做这个改变,看看它对性能有什么影响。
在做了这个改变之后,重新运行cargo bench的结果如下。
#![allow(unused)] fn main() { find time: [47.495 ms 47.843 ms 48.279 ms] change: [-15.488% -14.760% -13.944%] (p = 0.00 < 0.05) Performance has improved.Found 4 outliers among 100 measurements (4.00%) 4 (4.00%) high severe }
很好! 即使在这样一个简单的改变之后,我们已经观察到了性能上的明显改善。既然一些简单的问题已经被解决了,让我们调查一下其他花费大量时间的地方。
加速反序列化
回顾一下火焰图,我们可以看到很大一部分时间都花在了解析来自 MongoDB Wire 协议(紫色)的响应上,然后通过serde(绿色)将它们反序列化为 Rust 数据结构。尽管每一个步骤都在执行类似的任务,但这两个步骤是需要的,因为bson crate只支持从Bson和Document Rust类型反序列化,而不是实际的BSON,即MongoDB wire 协议中使用的二进制格式。火焰图表明,这个过程消耗了大量的时间,因此如果这两个步骤可以合并为一个,有可能会带来显著的性能优势。
本质上,我们想从以下几个方面入手。
#![allow(unused)] fn main() { let bytes = socket.read(&mut bytes).await?; // read message from databaselet document = Document::from_reader(bytes.as_slice())?; // parse into Documentlet rust_data_type: MyType = bson::from_document(document)?; // deserialize via serde }
合并为:
#![allow(unused)] fn main() { let bytes = socket.read(&mut bytes).await?; // read message from databaselet rust_data_type: MyType = bson::from_slice(bytes.as_slice())?; // deserialize via serde }
要做到这一点,我们需要实现一个新的serde 的 Deserializer,它可以与原始BSON一起工作。这方面的工作相当广泛,而且相当复杂,所以我就不说细节了。serde文档中的 " 实现 Deserializer "部分为那些感兴趣的人提供了一个实现JSON的优秀例子。
那么,现在我们实现了 Deserializer并 更新了驱动程序 以使用它,让我们重新运行cargo bench,看看它是否对性能有任何影响。
#![allow(unused)] fn main() { find time: [30.624 ms 30.719 ms 30.822 ms] change: [-36.409% -35.791% -35.263%] (p = 0.00 < 0.05) Performance has improved.Found 5 outliers among 100 measurements (5.00%) 1 (1.00%) low mild 1 (1.00%) high mild 3 (3.00%) high severe }
棒极了! 平均迭代时间比上一次大约减少了36%,这与最初的基线相比已经有了很大的减少。现在我们已经实施了一些改进,让我们仔细看看结果。
分析结果
查看Criterion的HTML报告
Criterion支持生成一个HTML报告,总结最近的运行情况,并与之前的运行情况进行比较。要访问该报告,只需在浏览器中打开target/criterion/report/index.html。
作为一个例子,这里是比较基线和最优化的报告。
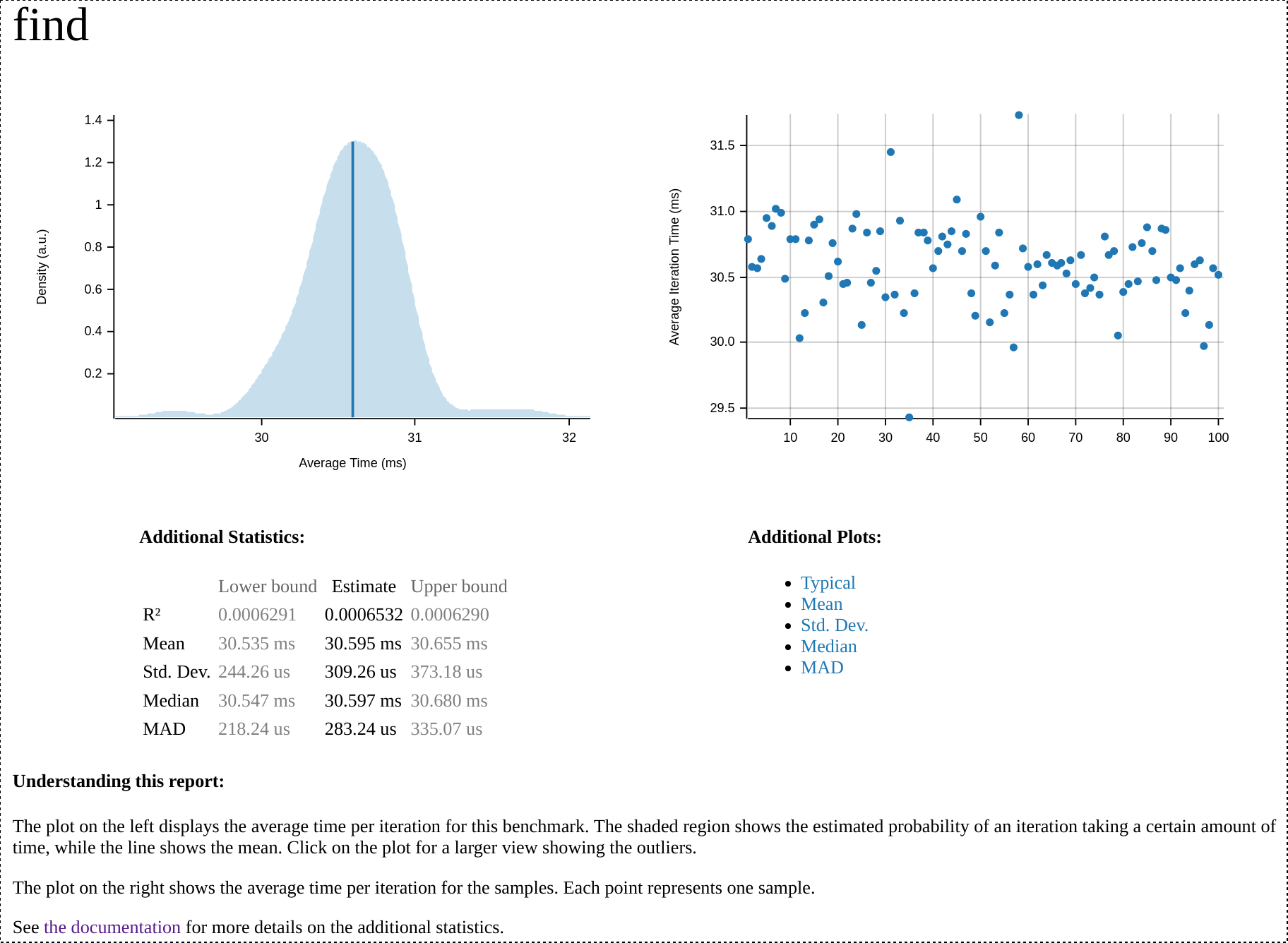
在报告的顶部,我们可以看到最优化运行的总结,包括一个说明平均执行时间的图表和一个显示所有样本标准的散点图,以及一些其他图表的链接。下面是最近一次查找基准运行的该部分的屏幕截图。
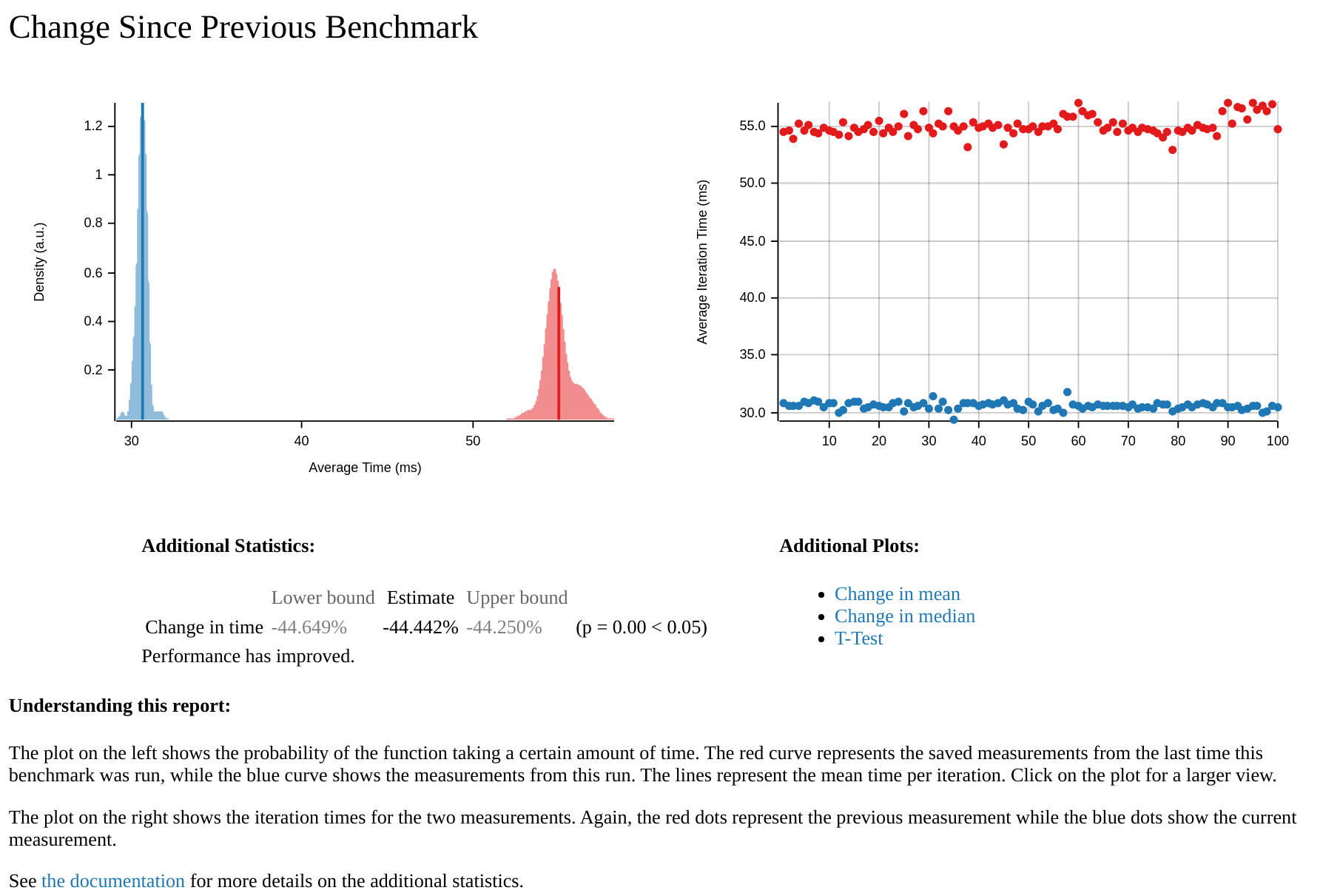
在报告的底部,有一个最近两次运行的比较,较旧的运行(基线)为红色,较新的运行(优化后的)为蓝色。下面是优化后的mongodb版本与未优化的基线比较的部分的截图。在其中,我们可以看到,未优化的基线显然要比优化的慢得多。从分布的广度来看,我们也可以看到,优化版的性能比基线版的更稳定。
这些报告是超级有用的工具,可以直观地看到因性能调优而发生的变化,而且对于向他人介绍结果特别有用。它们还可以作为过去性能数据的记录,消除了手动记录结果的需要。
使用wrk进行压测
虽然微基准对隔离行为和识别瓶颈非常有用,但它们并不总是代表真实的工作负载。为了证明所做的改变确实提高了性能,并且没有过度适应微基准,在真实世界的场景中进行测量也是很有用的。
对于像mongodb这样的异步数据库驱动来说,这意味着有大量并发请求的情况。一个生成这种请求的有用工具是wrk工作负载生成器。
要安装wrk,你需要clone repo并从源代码中构建它。
#![allow(unused)] fn main() { git clone https://github.com/wg/wrkcd wrkmake./wrk --version }
如果成功了,你应该看到wrk的版本信息。关于更具体的安装说明,请看 wrk 的 INSTALL 页面。
在启动了一个actix-web服务器(在release 模式下运行),它将对每个GET请求执行查找,我用下面的调用将wrk指向它。
./wrk -t8 -c100 -d10s http://127.0.0.1:8080
这将在10秒内运行一个基准,使用8个线程,并保持100个HTTP连接开放。
使用未经优化的驱动程序,我看到了以下结果。
Running 10s test @ http://127.0.0.1:8080 8 threads and 100 connections Thread Stats Avg Stdev Max +/- Stdev Latency 7.83ms 2.06ms 26.52ms 73.81% Req/Sec 1.54k 379.64 7.65k 91.02% 122890 requests in 10.10s, 205.45MB readRequests/sec: 12168.39Transfer/sec: 20.34MB
优化后,我看到的却是这样的结果。
Running 10s test @ http://127.0.0.1:8080 8 threads and 100 connections Thread Stats Avg Stdev Max +/- Stdev Latency 4.03ms 1.31ms 52.06ms 97.77% Req/Sec 3.03k 292.52 6.00k 92.41% 242033 requests in 10.10s, 404.63MB readRequests/sec: 23964.39Transfer/sec: 40.06MB
.这意味着吞吐量几乎增加了100%,真棒!这意味着我们基于微基准的优化对实际工作负载有非常显著改善。
下一步
在这篇文章中,我们已经看到了如何只用一些基本的性能技术(生成火焰图、基准测试)就能在你的Rust应用程序中实现显著的性能改进。这方面的过程可以总结为以下步骤。
- 使用
criterion运行一个基准,以建立一个基线 - 通过
cargo flamegraph识别瓶颈 - 尝试解决瓶颈问题
- 重新运行基准测试,看看瓶颈是否得到解决
- 重复进行以上步骤
这个过程可以反复进行,直到达到一个令人满意的性能水平。然而,随着你的迭代,改进可能会变得不那么显著,需要更多的努力来实现。例如,在mongodb的例子中,第一个大的改进来自于更明智地使用clone(),但为了达到类似的改进水平,需要实现整个serde 的 Deserializer 。这就引出了性能剖析如此重要的另一个原因:除了识别需要优化的地方外,它还可以帮助确定何时需要优化(或者反过来说,何时应该停止优化)。如果剩下的改进不值得努力,性能剖析可以表明这一点,让你把精力集中在其他地方。这一点很重要,因为无论某件事情如何优化,总是有改进的余地,而且很容易陷入过度优化的无底洞中。
总结
我希望这个关于 Rust 中性能剖析和基准测试的概述是有帮助的。请注意,将你的 Rust 应用程序或库,优化到技术上尽可能快,并不总是必须的。因为优化的代码往往比简单但缓慢的代码更难理解和维护。
更重要的是,你的应用程序或库要满足其性能预期。例如,如果一个CLI工具的自我更新需要50毫秒或100毫秒,尽管有可能减少50%的运行时间,这并没有什么区别,因为100毫秒完全在这种功能的预期性能水平之内。然而,对于那些性能没有达到预期的情况,这篇文章中所概述的过程可以非常有效地产生优化,正如我们最近对mongodb crate所做的改进中所看到的。
广告时间
我们最近发布了mongodb crate的 v2.0.0版本,其中包含了这篇文章中提到的性能改进,以及大量的新功能,包括对事务的支持。如果你对用Rust编写Web应用程序感兴趣,如果你需要一个数据库,请查看MongoDB Rus t驱动。